Scrapy:根据目录来下载github上的文件

2018-06-14 18:07 493 0
写在前面
最近在学习Python的语法,刷刷LeetCode什么的。熟悉之后,就想着写一个爬虫实际运用一下。
知乎了一下,然后看了scrapy的文档 ,就开始动手了。
那么爬什么呢❓
当时就想着写一个根据目录来下载github仓库文件的spider。因为以前下载github仓库的时候要么只能根据git地址clone整个repo,要么只能通过octoTree或者insightio下载单个文件,然而经常会有需要下载单个或者多个目录的情况,所以就想着写一个根据目录来下载github上文件的爬虫。
开始
要开始,当然是推荐看官方的入门教程了。
这里简单描述下步骤:
##1.创建项目
scrapy startproject scrapy_github_dir
##2.创建爬虫
scrapy genspider app github.com
##3.写逻辑或者进行设置等等
##4.运行爬虫,爬取路径是github上的目录或者文件
scrapy crawl app -a urls = https://github.com/ditclear/BindingListAdapter/tree/917e254f527d101e3f583c38739a61f3bcffbc11/library-kotlin
主要的代码都在app.py里,当运行scrapy genspider app github.com时会主动帮你生成它
import scrapy
from ..items import ScrapyGithubDirItem
class AppSpider(scrapy.Spider):
name = 'app'
allowed_domains = ['github.com']
content_domains = 'https://github.com/'
start_urls = []
def __init__(self, urls=None, *args, **kwargs):
super(AppSpider, self).__init__(*args, **kwargs)
self.start_urls = urls.split(',')
//运行scrapy crawl xx 后,处理response
def parse(self, response):
raw_url = response.css('a#raw-url').xpath('@href').extract_first()
if raw_url:
href = self.content_domains+raw_url
print("scrapy from href --> ", href)
yield scrapy.Request(href, callback=self.parse_link)
else:
for link in response.selector.xpath('http://a[@class="js-navigation-open"]/@href').extract()[1:]:
href = self.content_domains+link
yield scrapy.Request(href, callback=self.parse)
def parse_link(self, response):
responseStr = str(response).strip()
url = responseStr.strip()[5:len(responseStr)-1]
print('download from url --> ', url)
item = ScrapyGithubDirItem()
item['file_urls'] = [url]
return item
当运行scrapy crawl xx 后,会在parse(self, response)方法处理response。
处理response,简单理解来就是通过css选择器和xpath来找到你想要的内容,比如text/img/href等等,获取到想要的内容后,保存到文件、数据库,期间掺杂着一些scarpy的配置。
通过分析网页源文件:
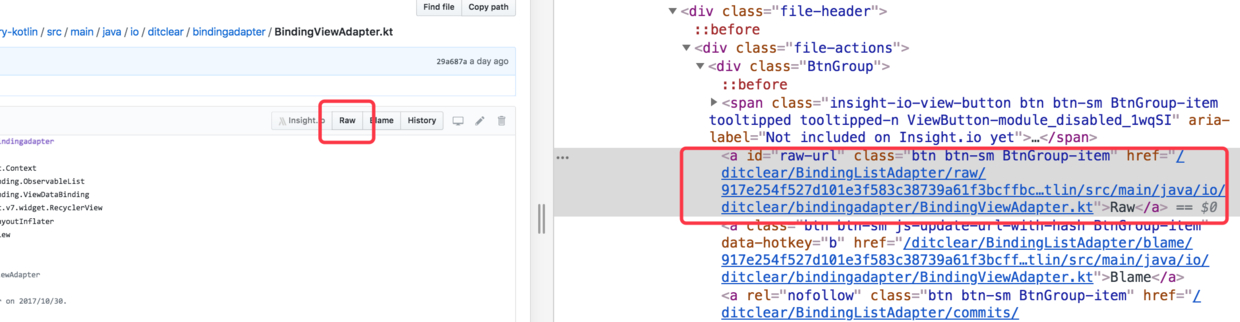
可以看到单个文件的下载链接在id为raw-url的a标签中,所以我们需要找到这个标签然后获取到想要的链接。
raw_url = response.css('a#raw-url').xpath('@href').extract()
这里的意思是通过css选择器找到id为raw-url的a标签,然后获取到a标签的href参数,最后提取出来以列表的形式返回。
如果没有返回那么则表示当前request的url不是具体的某个文件,而是一个目录。
如果当前url是目录
分析一下目录的response的结构,通过css选择器和xpath继续找到其下一级的文件
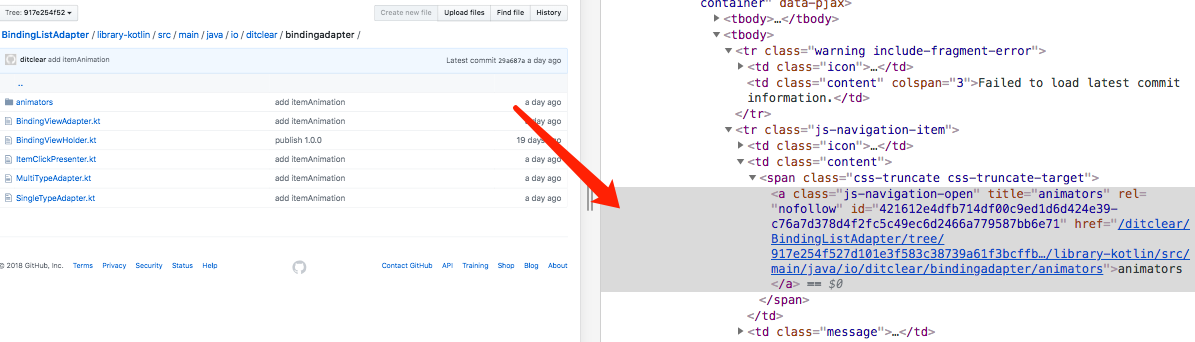
同样的,找到这个地址
response.selector.xpath('http://a[@class="js-navigation-open"]/@href').extract()
需要注意的是返回的列表中,第一个索引的值指向的是上一级目录,所以需要将其排除掉。接着递归调用当前的parse方法,直到爬取到文件为止。
if raw_url:
//爬取具体的文件
yield scrapy.Request(href, callback=self.parse_link)
else:
//如果是目录,递归直到爬取到文件为止
for link in response.selector.xpath('http://a[@class="js-navigation-open"]/@href').extract()[1:]:
yield scrapy.Request(href, callback=self.parse)
代码不多,顺利的话半天就能成功。

写在最后
回顾一下,能发现没怎么就已经写好了。而爬虫简单看来就是通过css选择器、xpath或者正则找到需要的数据,然后进行想要的处理,期间夹杂着递归的逻辑和算法,当然这只是初见scrapy,不过已经能发现Python以及Scrapy的强大了。
github地址:https://github.com/ditclear/scrapy\_github\_dir
参考资料:
http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html




